IJC API
Table of contents
{success} Javadoc IJC is modular, allowing for easy expansion and development. Because of this, the API is split into several modules. There are four commons modules which provide some basic (and familiar) objects and utilities that are not IJC dependent. The most important module is the Discovery Informatics Framework (DIF) API , which provides the data model and persistence tiers for applications that need to use chemical and biological data. Also very important to IJC development are the user interfaces defined in the IJC Core Module API and the Forms Model Module API . This document will provide an overview of the important parts of the API to assist developers with customising IJC for their needs.
Discovery Informatics Framework
DIF is modelled strongly around the relational database paradigm, but maintains a higher level of abstraction to support the more complex nature of chemical and biological data. For instance, whereas a relational database deals with tables and columns, DIF works with entities and fields. As an illustration, whereas a database column can hold a simple text value or a number, a DIF field can have a richer data type, such as a structure, or a dose-repsonse curve. DIF can also be used outside IJC (for instance to create a web browser based application), or could be used to build a web application that accesses databases based on ChemAxon technology.
There are two key components to DIF: DDL (Data Definition Layers) and DML (Data Manipulation Layers).
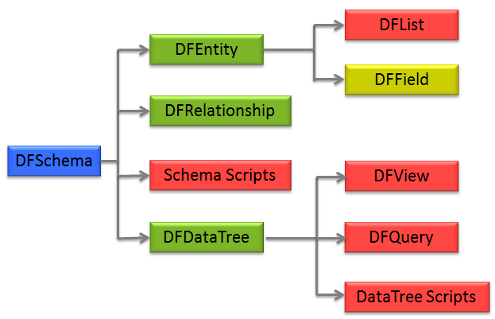
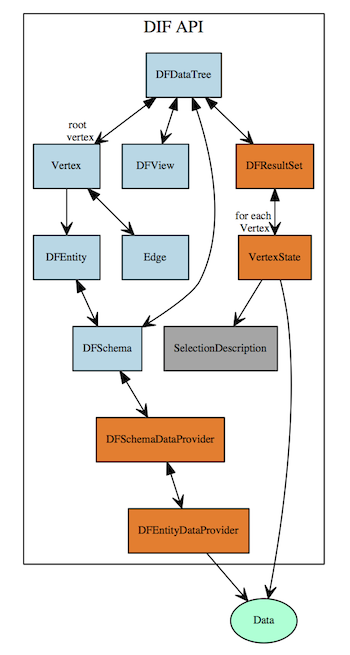
DDL : This is about static models, providing 'definitions' to components, such as schema, relationships, entities (eg tables), fields (eg columns), and so on. DDL is also where user-owned objects are defined, which are: views, lists, queries and scripts. DDL contains the utilities for manipulating the structure of the objects within the DIF. The terminology used in DIF stems from the entity-relationship model . On top of that is built the data tree, represented as a subset of a complex graph of entities and relationships. As the data tree is the root of the data graph, it adopts terminology stemming from graph theory . Nodes in the data tree are called vertices and relationships between them are called edges. It is important to note that entity-relationships are not oriented, and neither is the entity-relationship schema. However, data trees are oriented and directional. A vertex is a wrapper around an entity, and an edge is a wrapper around the relationship (which is directional specified as a data tree is an oriented graph). The root object for DDL objects is schema (DFSchema , which defines all entities, relationships, and datatrees down graph from the schema point). Different levels of DIF provide containers for all types of items (DFItem), and is also the entry point for all data manipulation objects (DML). The 'ownership' of the containers is shown below, indicating that DFSchema has containers for entities, relationships, datatrees and schema scripts.
 |
 |
|---|
DML : This is part of the DIF module used for manipulating the actual data, such as inserting/deleting rows, modifying values, and running queries (which includes relational data manipulation and searching across tables). This lays on top of DDL, which provides the entry point into the schema via the method
schema.getDataProviderEach DFEntity has its own DFEntityDataProvider. Changes to architecture of the DFEntity happen via DDL methods, while changes to the data of the DFEntity happen via DML methods on the DFEntityDataProvider.
While these two modules are separate in their function and methods, they both share the common (and very important) concept of environments and locks.
Locks
Most DIF write methods use locking. This effectively means that the object being written to is 'locked' so that no other changes can be made while your method runs. Before the method is called, you must obtain the lock for that item, put it in the DFEnvironmentRW (see below), and then pass the environment to the data modification method. These are controlled via the interface DFLockable . The lockable for an item provides only a single DFLock , at the same time.
It is important to determine which area of the DIF to lock for the method at hand. The various
getLockable()methods are discussed on the DFLockable page, separating out the DDL or DML items that can be used to lock schemas, entity data providers, user-owned items, and so on. The most important lock is the global DDL lock for shared items, which is used when altering schema, entities, etc. Beyond this is the global DDL lock for user specific items (DFView, DFQuery, DFList).
Environments
In DIF methods, everything is executed in the same thread, with no return until the operation is complete. This poses a problem for long-running process, and potential occupation of the threads necessary for updating of the GUI. In order to provide feedback, and move long-running methods to the background, environments were introduced. These can pass common parameters to methods, as well as provide feedback on the background process. Currently the two functions of an environment are a holder for feedback (via DFFeedback ) and a lock. If the method does require a lock, then a simple read-only environment is needed (with no locks). In this case the RO environment is a holder for feedback on the method running.
There are three types of methods:
-
No modifications : Those performing queries, reading a file, performing calculations, etc. These methods use the interface DFEnvironmentRO (read only). This allows for long running methods to provide notifications about progress and errors.
-
Modifying methods : If a method requires writing (editing an infrastructure or altering data), then the method requires a read-write environment, controlled via the interface (DFEnvironmentRW ). Because no method is asynchronous, the appropriate part of the DIF (be it data tree, entity, or entity data provider) must be 'locked' in order to prevent other changes from happening at the same time. This lock is created separately and then passed into the DFEnvironmentRW.
-
Fast methods : Methods which happen very fast do not require an environment.
Environments can be created using the EnvUtils class of methods. Feedback can be passed back from either type of environment using the
getFeedbackmethods. It is worth noting that DFEnvironmentRW is a subinterface of DFEnvironmentRO, and a RW environment can be created from an existing RO environment via the method
EnvUtils.createRWFromRODDL Capabilities
Capabilities help to extend the basic DFItems. For example, DFField could be a column in a file, or in a database. Capabilities are a way to differentiate the two. It can also further define datatypes once it is determined that the DFField belongs to a database, leading to capabilities such as DFFieldStructureCapability. These are important for defining new objects. Capabilities can have properties (getSomething/setSomething), but property change support is implemented on the level of the master/owner object DFItem. The interface DFCapability lists all known subinterfaces (capabilities).
New Types
All DFItems belong to each other through the DFContainer interface. This is a simple hierarchy, in which the container has lists of types of the items it contains (eg the DFSchema container has lists of the potential new types of DFDataTree, DFEntity, and DFRelationship). The parent Items will have a container fetching method, such as
getEntitiesin the DFSchema interface. This method will return the entities container. It is through the container interface that new objects of type are created, via DFNewType.
DFNewType is the object that can create the new item, based on the context that the NewType (and thus container) came from. There are several options within DFNewType for each kind of DFItem - thus, knowing the DFCapability needed for the desired item is necessary to create the new object. This simplifies the process as the list of newTypes is extensive. NewTypes themselves can either create a new object, or a newType which takes an existing database artiface and promotes it to a recognizable item in IJC ("promoting" an item in the GUI). The API for DFNewType provides further details on how to use NewType to get the capabilities for the object/container in question.
Creating new DFItems via DFNewTypes is overtly complicated. Since IJC version 5.8, there are now utility methods that simplify the creation of certain DFItems. DFFields is an excellent example, now containing the
createBooleanField, createTextField, createIntergerFieldand more. This removes the need to search for NewTypes, or be concerned about the container. Not all field types are currently supported (chemical terms and calculated fields are not done yet), but are being developed.
Javadoc
Instant JChem is composed of many modules (currently approximately 45), but many of these contain only 3rd party libraries. The number of modules that need to be used for extension is relatively small. JavaDocs for these key modules is being prepared. Not all are currently ready. The most important module is the DIF module that defines the lowest tier mentioned above.
Please note that the stability differs for different parts of these APIs. We try to indicate this in the JavaDocs.
{info} All these javadocs are linked together and reflect the module dependencies.